Host classification via IP-ID

At the dawn of the Internet a 16 bits field was introduced in the IPv4 packet to assist network-layer fragmentation and reassembly processes: the IP identifier (IP-ID).
Over the years, the IP-ID was mostly implemented as a simple packet counter: however, this behavior has been discouraged for security reasons and other policies, as the use of random values, have been suggested. Nowadays, things seem to be changed: with an Internet-wide census we reveal which are the most prevalent IP-ID implementations.
1. A brief history of IP-ID, implementations and applications
In the very first document, the RFC 791, valid IP-ID choices were not fully specified: it was only stated that each IP packet must have a unique IP-ID for the trio of source, destination and protocol within the maximum datagram lifetime. This made possible its exploitation and abuse for a range of tasks, from counting hosts behind NAT, to detect router aliases and, lately, to assist detection of censorship in the Internet at large.

Yet, over the years, with technology evolution, the IP-ID has been the object of numerous changes (for instance, to enforce more secure policies), and about a decade ago the different ways in which it could be set by the operating system were listed and detailed in RFC 4413 and RFC 5225. As a result, a wider range of behaviors can be expected nowadays. Indeed, the IP-ID field can be set in different manners: as a global counter (incremented by one at every new packet), or as a local counter (in which separate counters are kept for different destinations), or as the output of a pseudo-random number generator or finally as a (typically null-valued) constant.
The sole quantitative assessment of IP-ID behavior over multiple classes dates back to 2013 and is limited to 271 Top Level Domains TLDs. This study finds the IP-ID implementations to be so distributed: 57% global, 14% local, 9% constant, 1% random/other. The remaining works concentrate instead on assessing the popularity of just the global implementation being it the only focus of their studies, given its invaluable help to infer a wealth of information concerning the network.
2. Measure and classify the IP-IDs
These policies can be inferred by leveraging two vantage points sending packets that arrived interleaved at the target host: the resulting sequences are illustrated in the following pictures (where the two vantage points are represented as a white box and a purple circle).
In our study, we first propose a framework to robustly classify the different IP-ID behaviours with only a handful of IP packets. We rely on active probing from a single host using IP spoofing to precisely control packet interleaving at the generation. Despite being only minimally intrusive, our technique is significantly accurate (99% true positive classification), robust against packet losses (up to 20%) and lightweight (few packets suffices to discriminate all IP-ID behaviors).
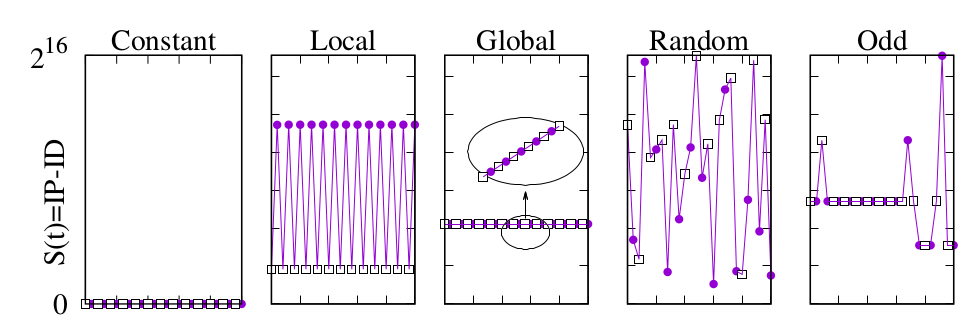
This framework is based on the definition of highly discriminative features with known expected values, that we train over a dataset with manually constructed ground truth, that we make available to the community. Notice that by employing a supervised technique, we are also able to cope with odd behaviors such as those due to load balancing middleboxes, or host implementations using the wrong endianness. The ground truth dataset we release can of course be useful to validate any other technique you may wish to define, so don’t hesitate to grab a copy!
3. An Internet-wide Census
Given that our classifier is lightweight and robust to losses, we finally performed a census of the IPv4 address space. We do so by actively probing one alive target per each routable /24 block. This outcome provides a picture of Internet-wide adoption of the different IP-ID implementations.

Specifically, whereas the global counter (18% of occurrencies in our measurement) implementation was the most common a decade ago, we find that other behaviors (constant 34% and local counter 39%) are now prevalent. We also find that security recommendations expressed in 2011 are rarely followed (random, 2%). Finally, our census quantifies a non marginal number of hosts (7%) showing evidence of a range of behaviors, that can be traced to poor or non-standard implementations (e,.g., bogus endianness; non-standard increments) or network-level techniques (e.g., load balancing, or exogenous traffic intermingled to our probes confusing the classifier). To make our findings useful to a larger extent, we make all our dataset and results available.
 Want to know more? Read our paper!
Want to know more? Read our paper!
Publication
Salutari, Flavia and Cicalese, Danilo and Rossi, Dario, A closer look at IP-ID behavior in the Wild, International Conference on Passive and Active Network Measurement (PAM) Mar. 2018.